Korean Semantic Textual Similarity API
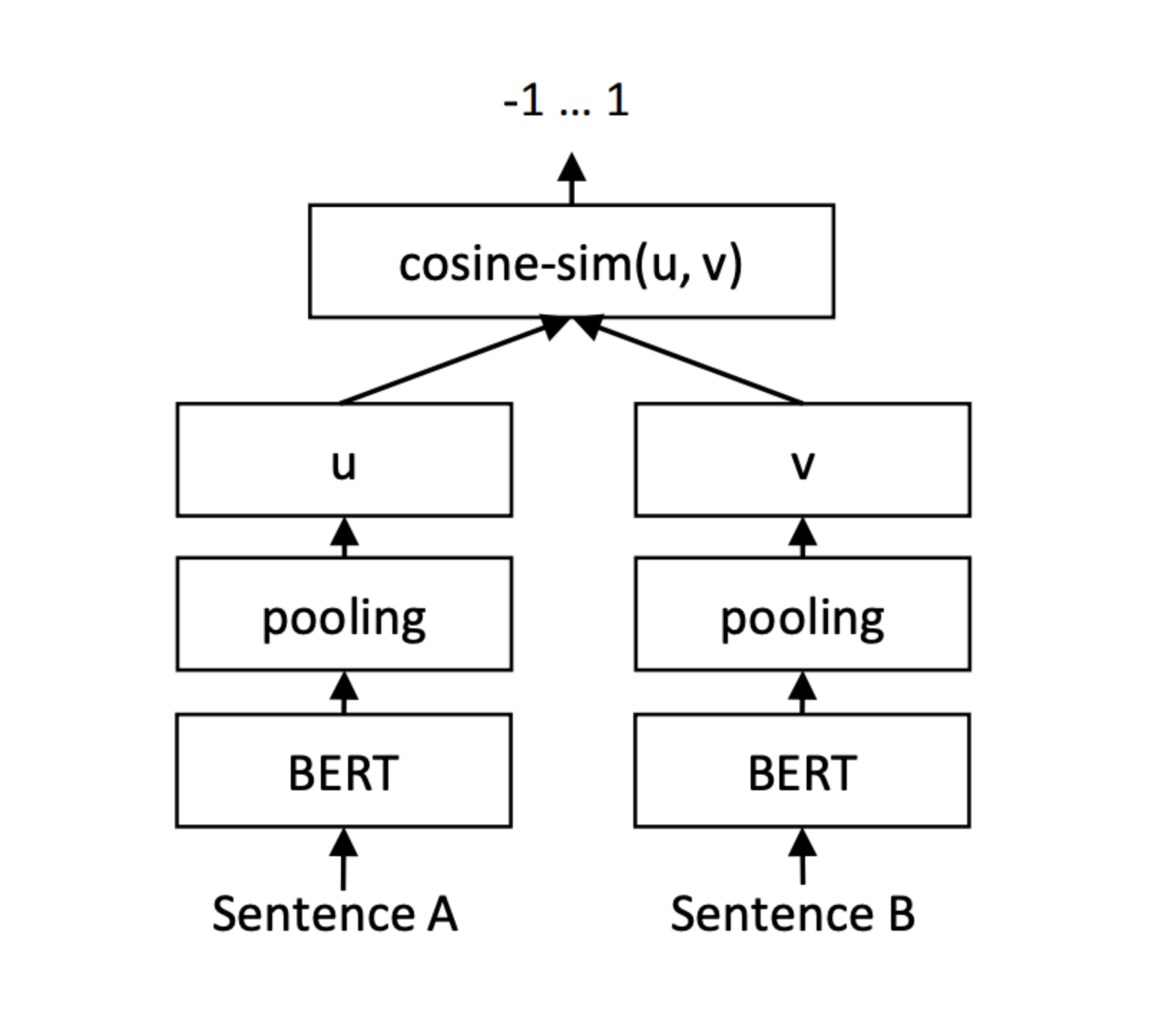
Created a model scoring semantic textual similarity between two sentences, using Klue/Roberta-large pre- trained model along with the klue-sts dataset. Roberta model was used in a weight sharing Siamese structure, producing mean pooling value for each of the two outputs, which would be used to calculate the cosine similarity between the input sentences within the range of 0 to 5. The best model found through random searching of hyper parameters showed pearsonr correlation of 0.882, along with F1 score of 0.835, given a threshold of three for the initial prediction. The model was implemented as a Rest API, predicting the STS score for 1:1 , 1:N sentence inputs.
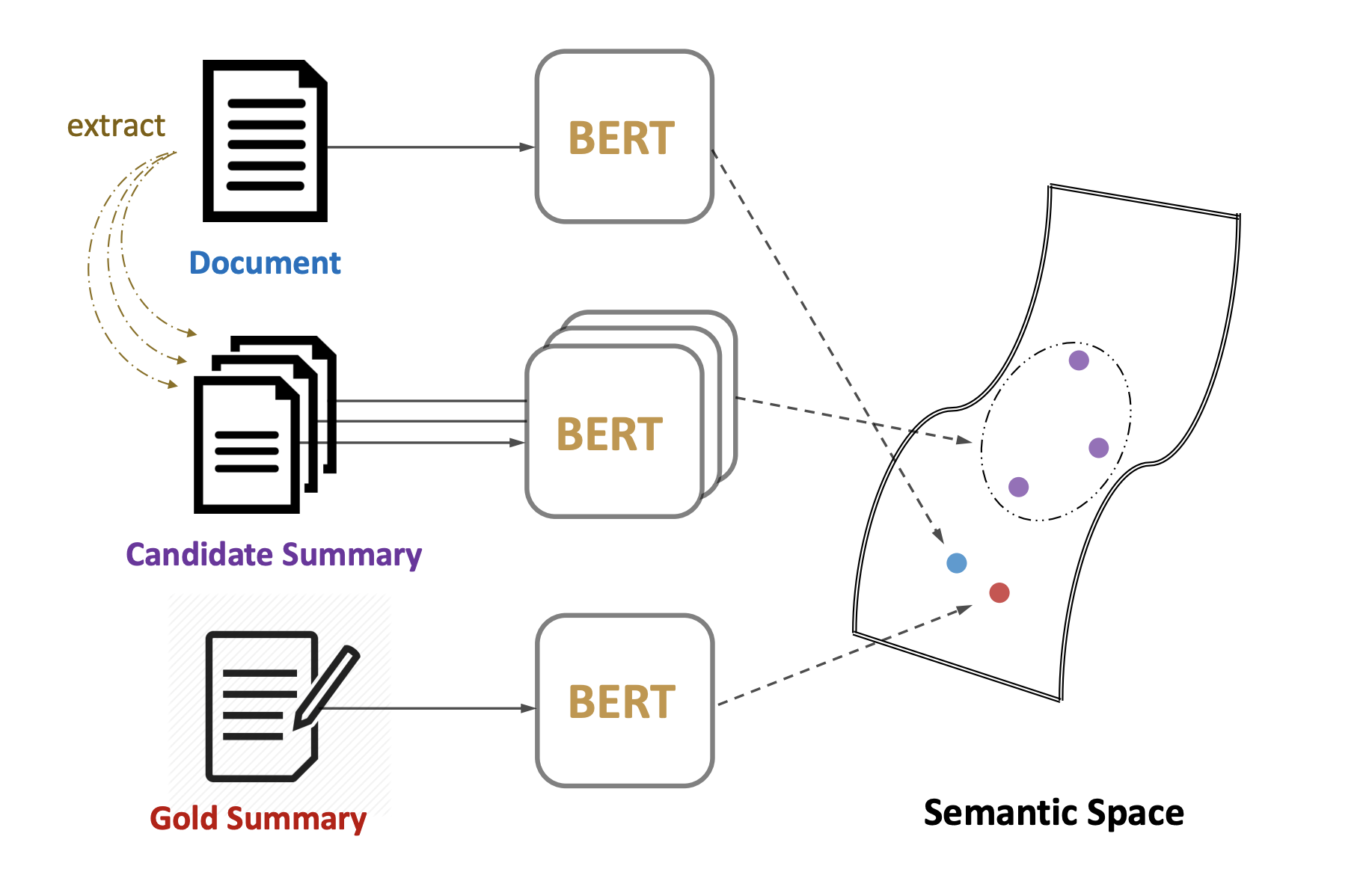
MatchSum
Focused on preprocessing and implementing MatchSum extractive text summarization model without Gine- tuning process. As BertSum trained in Korean dataset is not available, modiGied version of Greedy-Selection algorithm from BertSum was used to score and prune sentences for each articles. MatchSum, as described in the paper, matches CLS token vector of the original text with candidate summary created from pruned article along with gold summaries written by human. Although no functioning summarization model was produced, the project helped to educate myself with both MatchSum and BertSum along with oracle summary generating algorithms and deeper understanding on the Rouge scores.
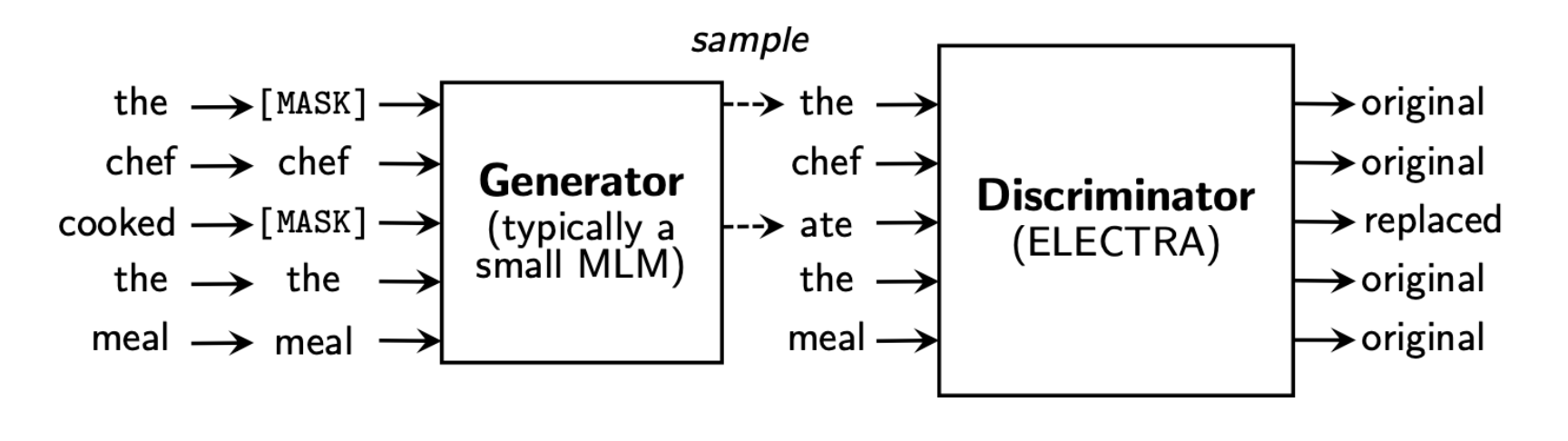
Korean Hate Speech Detection
Using a Korean Hate Speech Dataset, Gine-tuned a pre-trained KcELECTRA-base model to classify a short comment to one of three labels (Hate/Offensive/None). For multi-class classiGication, the model include two linear classiGication layer which uses the CLS token output from Electra’s discriminator. Fine-Tuned model showed an accuracy of seventy four percent for its validation set. Having the model purposefully Gine-tuned upon an unchanging hyper parameters, the project allowed to observe the affects of altering preprocessing data, model’s parameters and different versions of the KcELECTRA model.
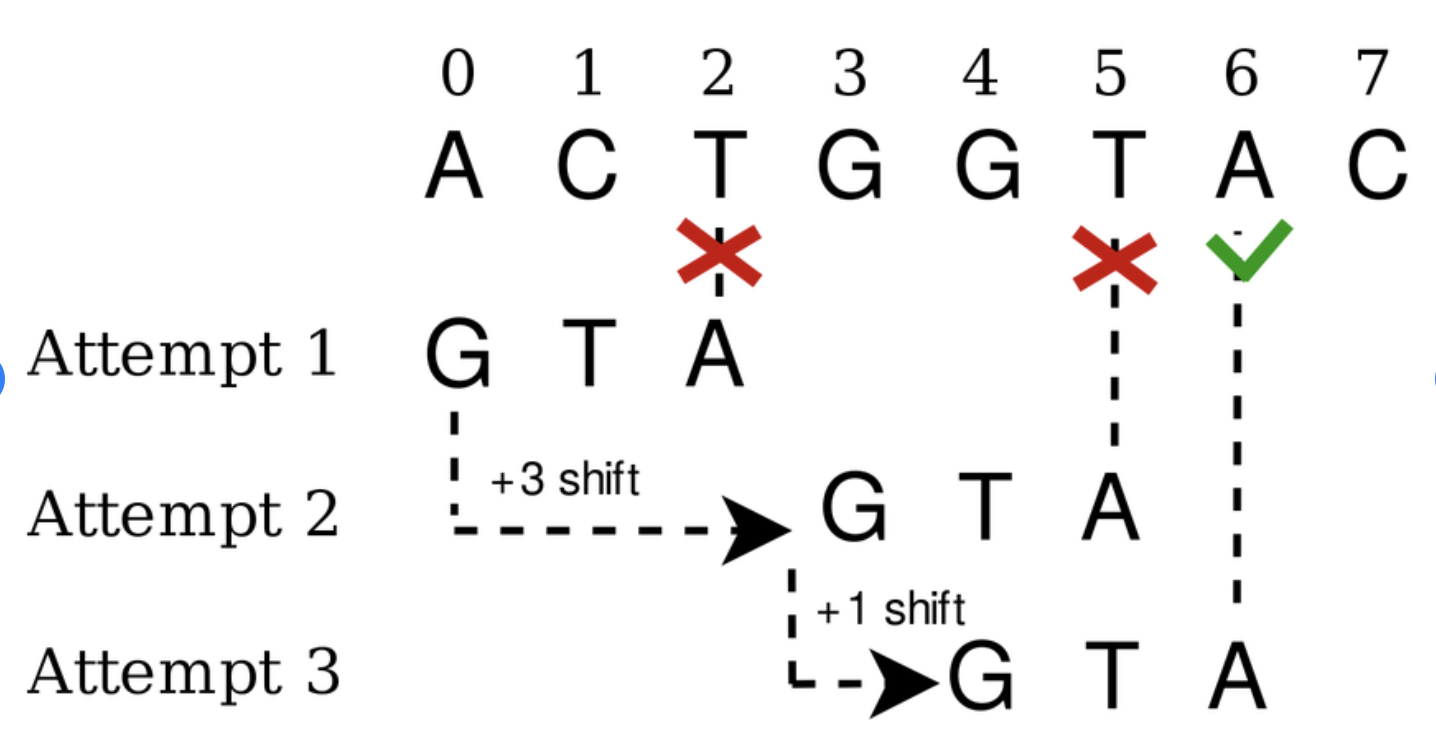
Boyer-Moore Algorithm for pattern matching
Implemented Boyer-Moore algorithm on Python for exact pattern matching. The algorithm consists of Bad Character heuristic and Good Suffix heuristic to determine the optimal shift of the pattern as it is matched to the text.