
Python3
지난 4년간 모든 대학 과제, 개인 학습과 프로젝트 진행시 파이썬을 주 언어로 사용하며 언어에 대한 역량을 키워 갔습니다. 자바 또는 C++로 구성된 framework을 Python으로 재구현 한 경험이 많으며, 필요한 알고리즘을 표현하거나 제 3자의 코드를 읽고 이해하는데 어려움이 없습니다.
University of Rochester '21
Class of 2021로 University of Rochester을 졸업한 박홍준 입니다. ML/DL 자연어 처리 분야를 열정적으로 탐구하고 있고 자연어 처리의 전반적인 기본 지식과 분류/문서 요약을 독학하고 있습니다. 현재 취업 활동중에 있으며, 데이터 분석가, ML/DL, 데이터 분석등의 포지션을 찾고 있습니다.

지난 4년간 모든 대학 과제, 개인 학습과 프로젝트 진행시 파이썬을 주 언어로 사용하며 언어에 대한 역량을 키워 갔습니다. 자바 또는 C++로 구성된 framework을 Python으로 재구현 한 경험이 많으며, 필요한 알고리즘을 표현하거나 제 3자의 코드를 읽고 이해하는데 어려움이 없습니다.

PyTorch는 Pandas, NumPy, TensorBoard 등의 다른 Library들과 함께, Transformer기반 딥러닝 프로젝트 진행시 필수로 사용하였으며, NLP분야 알고리즘과 논문 구현 연습 과정에서 꾸준히 사용하였습니다. NLP독학과 함께 사용하기 시작했으며, 학습에 필요한 데이터를 전처리부터 Hyperparameter Search하는 과정까지 pipeline을 제작할 수 있습니다.

Java는 2년간 대학 과제시 자주 사용하였으며 object oriented programming을 연습 하는데 가장 유용했던 언어 입니다. 다양한 Library을 사용해 보진 않았지만 원하는 알고리즘을 구현하는데에는 어려움이 없습니다.

데이터베이스 제작을 통해 MySQL을 학습했으며, 원하는 Query 작성 또는 제 3자의 Query 를 읽고 이해할수 있습니다. 테이블 구축/관계 생성/데이터 로드 등의 것들이 가능합니다

R은 여러 데이터 분석 과제를 통해 경험한 적이 있으며, 그중 섬의 입/출국 기록 데이터를 각 Column 별로 Examine 한 경험이 있습니다. 적합한 plotting으로 데이터의 시각화가 가능하며, Diagnostic plots with regression, ANOVA table, Box-Cox power transformation, log transformation, T-Test 등을 사용해 Data Analysis를 진행하였습니다.

HTML과 PHP는 local 서버에서 제작한 Query 시각화용 모의 보험 데이터베이스 웹페이지 제작시 처음 학습과 사용하였으며, 추후에 포트폴리오와 같은 개인 웹페이지 제작/업데이트 경험이 있습니다.
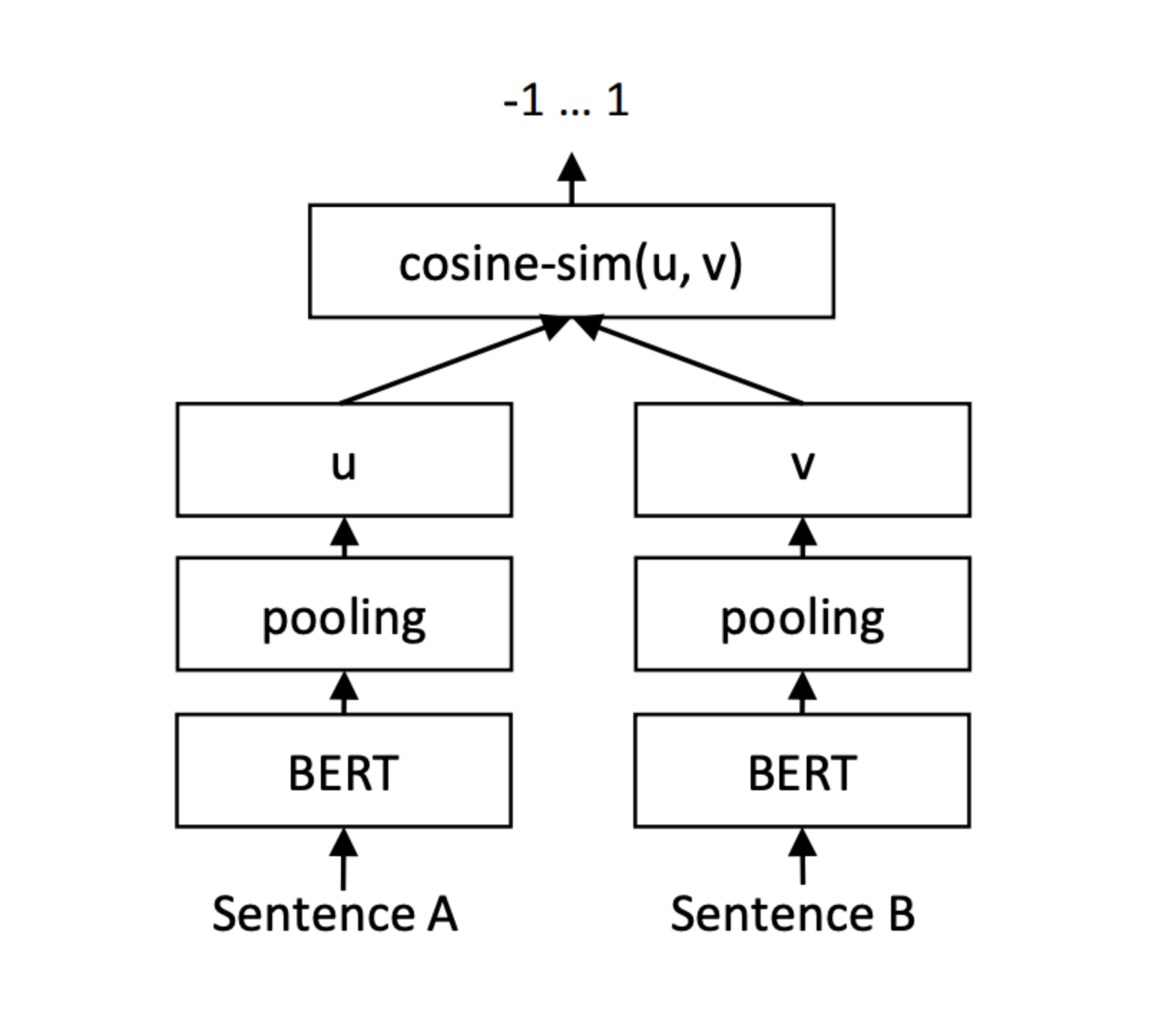
klue/roberta-large을 klue-sts benchmark에 Fine-Tuning한 ‘한국어 문장 유사도 유추 모델’을 API화 했습니다. 추론을 위해서 Weight를 공유하는 Siamese BERT Network을 사용했는데, 각 Sentence Embedding에 Mean-pooling Operation을 진행해 두 Fixed-size Sentence Embedding의 Cosine Similarity를 구하는 방식으로 설계하였습니다. 가능한 범위 내에서 random search로 hyperparameter search을 진행 하였고 Dev Set에 대해 0.894의 Pearson correlation과 0.849의 F1 Score의 성능을 보여 주었고, 이후 klue-sts와 kor-sts두 benchmark을 random sampling해 Fine-Tuning한 모델을 Rest API로 구현하였습니다. API는 1:1의 Semantic 유사도 점수를 Return하는 Get와 1:N의 유사도 점수를 Return하는 Post로 구성되어 있습니다.
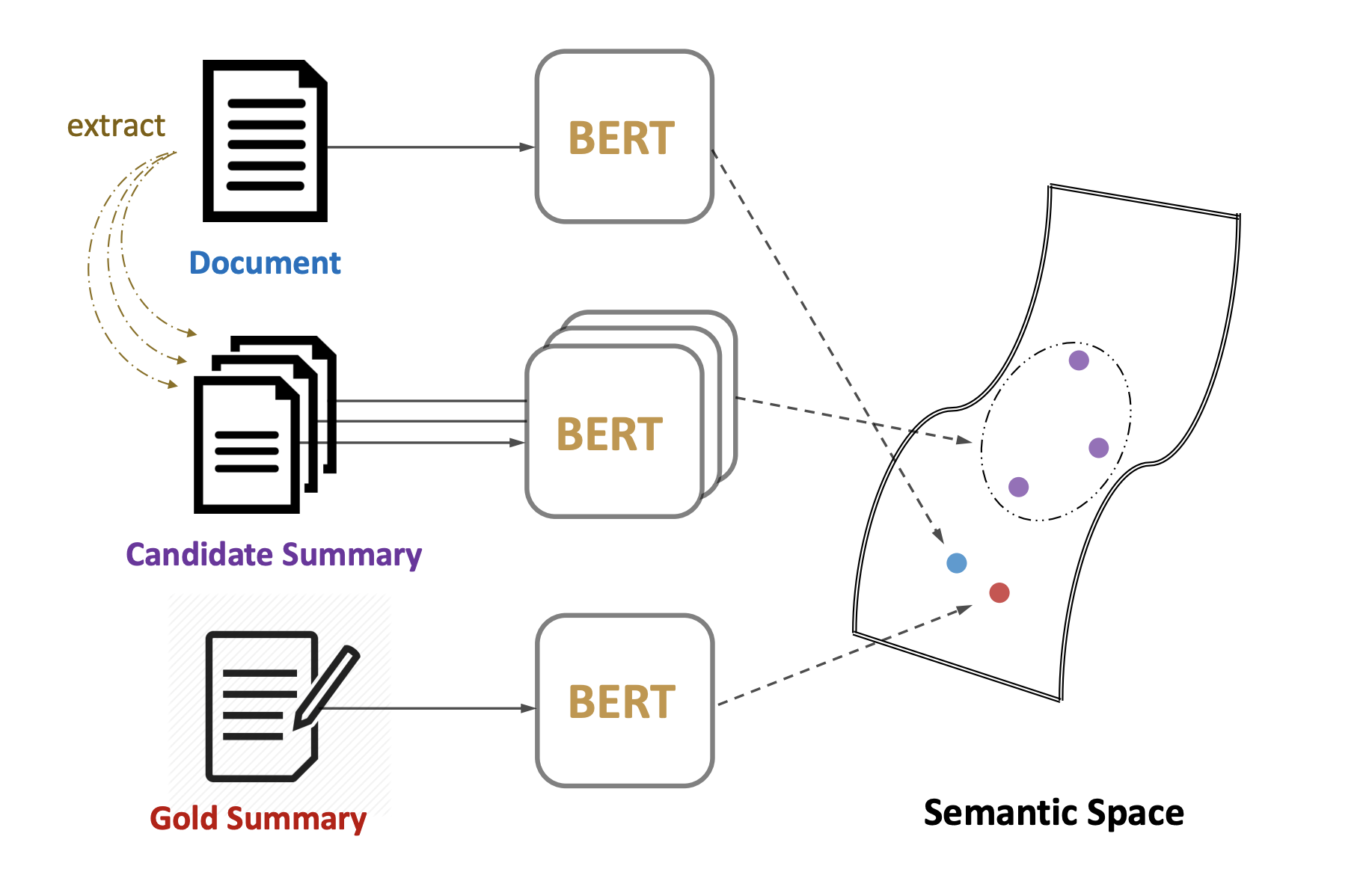
Google Colab에서 MatchSum 논문 그대로 Training을 진행하는데에 어려움이 있어 Model Framework와 데이터 셋 preprocessing에 중점을 두어 진행하였습니다. 학습의 핵심인 Candidate 추출 과정에서, 기사의 Pruning을 논문에서 사용한 BertExt로 점수를 부여해 진행하는 방식이 아닌, BertSum에서의 Oracle Summary 생성에 사용되는 Greedy-Selection과 Combination-Selection을 변형하여 사용하였고, 각 기사당 20개의 Candidate Summary을 생성하였습니다. 모델은 기사와 Gold Summary/Candidate Summary을 매칭하기 위해 CLS 토큰 벡터가 사용되며 Loss function으로는 MarginRankingLoss가 사용됩니다.
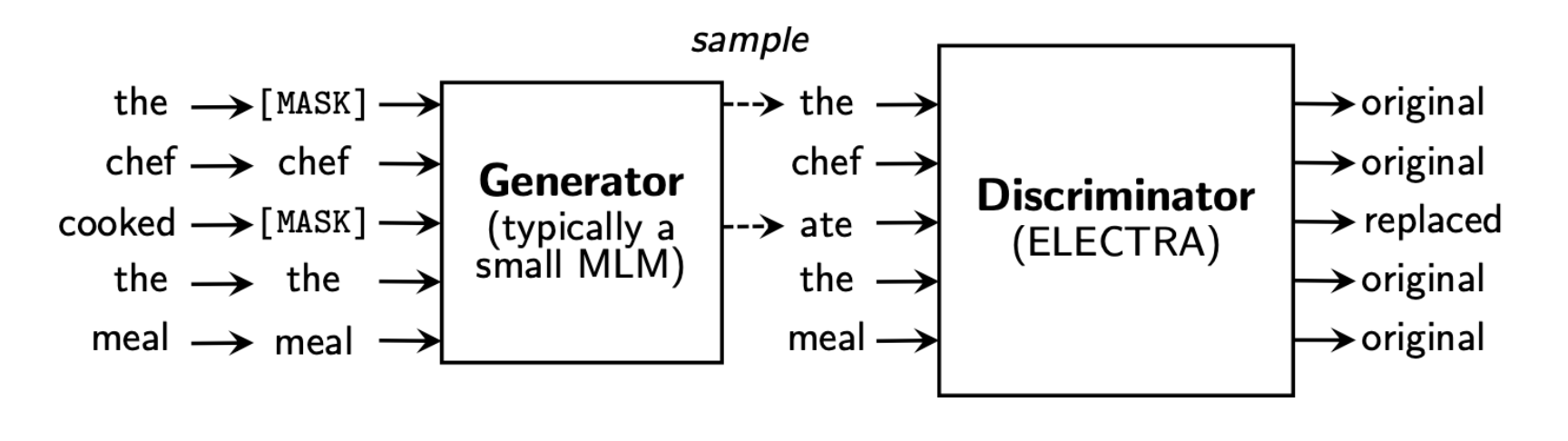
Kaggle Hate Speech Detection Competition을 위해 kcELECTRA-base discriminator을 주어진 데이터 셋을 사용해, 문장을 hate/offensive/none 세가지 Label로 분류하는 Multi-Class Classifier을 Fine-Tuning 하였습니다. 모델은 CLS토큰 벡터를 Classification Head로 통과시키며 Dev Set에 대해서는 74%의 정확도를, Test Set에 대해서는 Kaggle 점수 0.664점으로 표시 되었습니다.
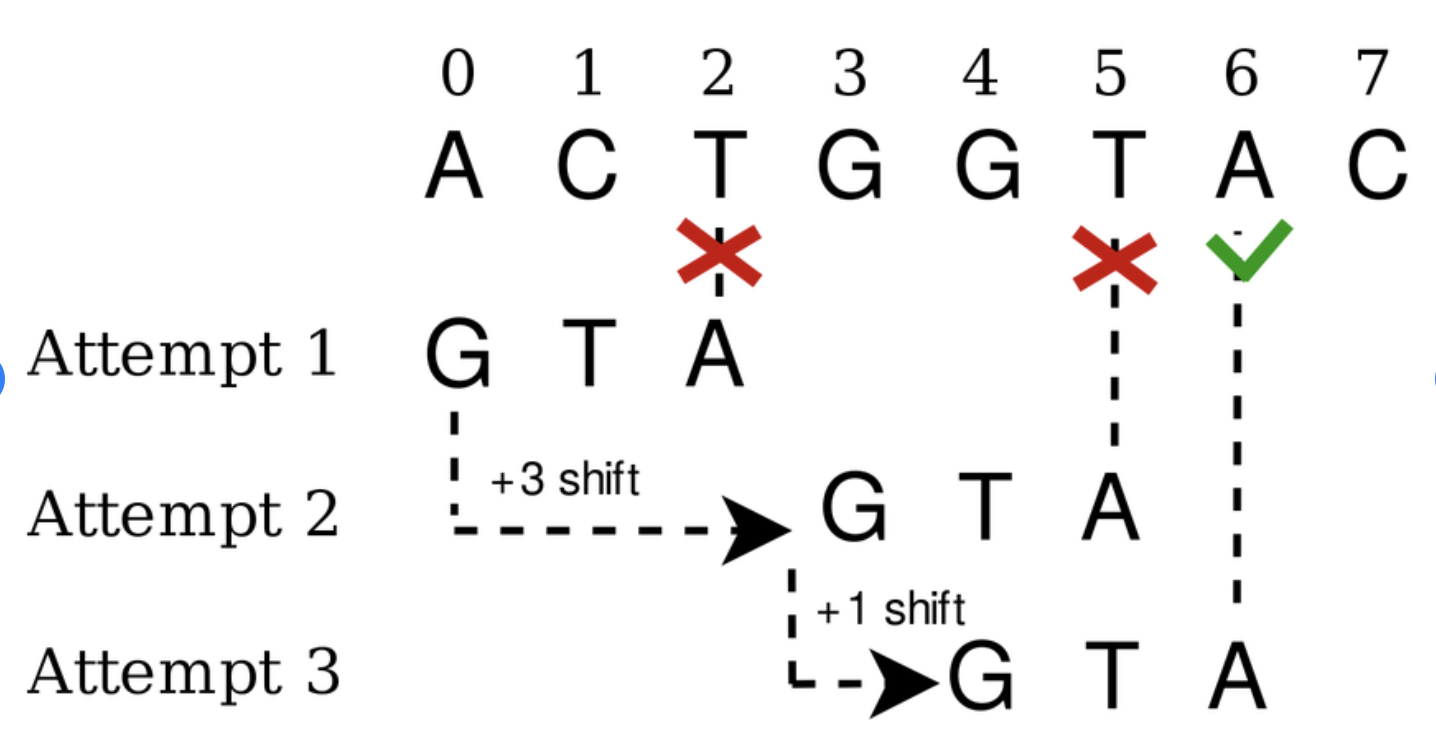
Exact Pattern Matching에 사용되는 Boyer-Moore 알고리즘을 구현하였습니다. Bad Character heuristic와 Good Suffix heuristic 두가지를 Preprocessing을 통해 문자열 매칭을 진행합니다.

명제 논리 추론 알고리즘 연습을 위해 Backus-Naur Form 문법을 나타낼수 있는 구조를 만들었고, 첫번째 추론 방법은 진리표 enumeration 알고리즘을 구현 하였습니다. 모든 AtomicSentence 에 True/False 값을 부여해 지식베이스가 쿼리를 entail 하는지 판단합니다. 두번째 추론 방식으로는 지식베이스와 쿼리의 문법을 논리곱 정규형으로 변형해 대입하는 귀류법을 기반으로 한 Resolution 알고리즘을 구현하였습니다. 대입하는 문법 표현 시 몇가지 제약이 있지만 올바른 인풋으로는 성공적으로 쿼리가 entail 될수 있는지 리턴합니다.
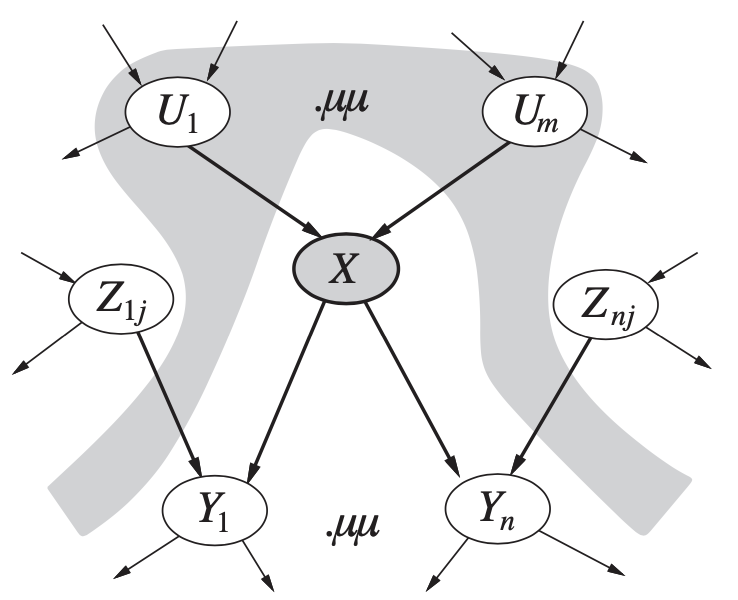
Bayesian Network structure을 구현한 뒤, 세가지 추론 알고리즘을 구현하였습니다. Enumeration을 이용한 첫번째 Exact Inference 알고리즘은 XMLBIF 파일에서 주어진 Evidence에 의거하여 각 쿼리 variable의 확률을 리턴합니다. 그 다음으로 Approximate Inference을 위해서는 Prior Distribution을 기반으로 모든 Event를 생성해 Evidence와 상반되는 Event를 제거하는 Rejection Sampling을 구현하고, 이후 Evidence와 일정한 Event만 생성해 Rejection Sampling의 비효율성을 보완하는 Likelihood-weighting 알고리즘을 구현하였습니다.
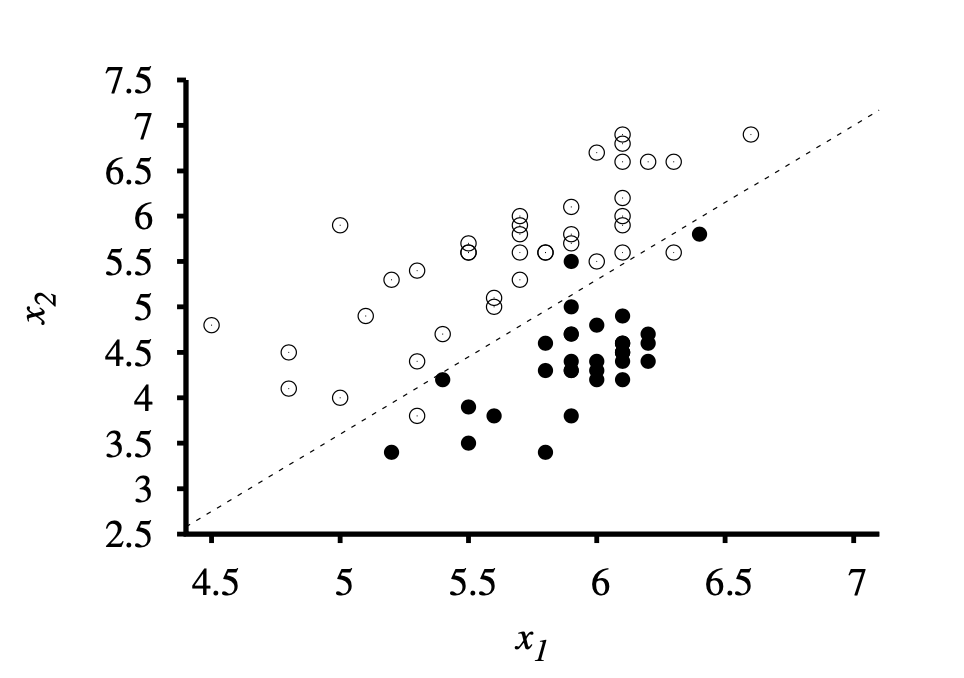
Information Gain의 최대화 하는 Attribute 선정 방법을 포함한 Entropy based Decision tree을 구현하였습니다. 알고리즘은 Overfitting을 방지하기 위해 관련 없는 Node를 Prune 하며, 학습시 tree의 정확도를 모니터 하였습니다. 추가로, Perceptron Learning Rule과 Hard Threshold을 사용하는 Classifier와, Logistic Regression을 바탕으로 분류하는 Classifier을 구현하여, Clean/Noisy 데이터와 Learning Rate가 학습에 미치는 영향을 학습할수 있는 계기가 되었습니다.
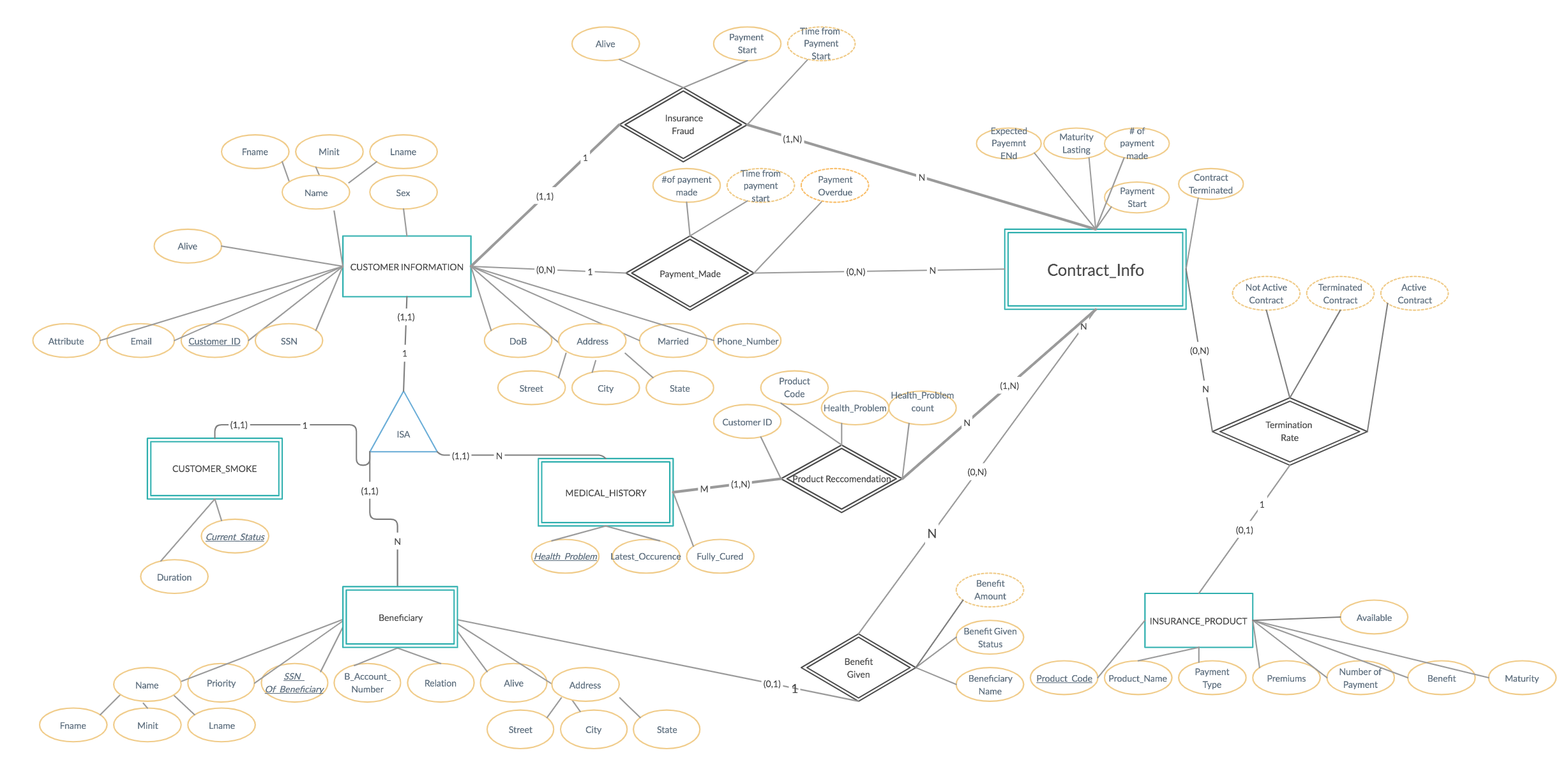
HTML과 PHP를 사용해 로컬 서버에 생명보험 정보를 보고 편집할 수 있는 웹페이지를 만들었습니다. 데이터베이스는 MySQL로 구축되었 으며, 데이터는 여섯 가지의 Entities와 다섯 가지의 Relationships로 이루어져 있습니다. 고객 계정으로 사이트에 접속하는 경우 non-key attributes를 수정 할 수 있는 권한을 가지게 되며, 고객의 건강 기록을 바탕으로 추천하는 보험 상품들이 소개됩니다.직원 계정은 더 많은 권한을 가지며 모든 데이터를 추가, 제거, 수정할 수 있는 권한을 가지게 됩니다. 프로젝트를 진행하면서 ER diagram, Relationship type mapping, 하고 데이터베이스의 시각화를 연습 할 기회가 되었습니다.